本文共 6702 字,大约阅读时间需要 22 分钟。
Android显示之应用界面绘制
越到上层,跟业务关联越直接,代码就越繁杂,Android上层显示的代码正是如此。此外,java语言本身繁复的特点(比C语言多了满屏的try-catch,比C++少了析构处理的优雅简洁,和更高级的语言scala、python等就别比了),更加剧了这一现象。
直接去看代码,往往会看得一头雾水,知其然而不知其所以然。在这时候,就要把代码扔掉,仔细去理清需要实现什么,怎么实现,画一幅架构设计图出来,然后再跟代码去对比。Android这部分代码并不是圣经,有很多待商榷的地方,心中要有主见,批判性地看。由于中间各种事耽搁,加上懒,一直没空写长篇博文,间隔了很长一段时间,请读者先回顾显示概述与下层显示:
另外,由于Android显示还是有不少人写的,某些模块有写得比较好的文章我就直接上链接,不自己写了,见谅。 下层显示关键词:SurfaceFlinger 上层显示关键词:View初步章节安排:
1、界面绘制 2、布局计算 3、硬件加速下层实现 4、典型控件 5、资源管理UI引擎设计原则
易用性
用户是很懒的,其实程序员也一样。 让应用开发者直接使用OpenGL去开发界面,无异于让他们赤手空拳打坦克。即便是使用图形引擎的接口,也已经相当繁琐了。
最理想的情形,是由编辑器搞定界面,所见即所得,配配参数就ok,如Unity3D。 一般都会提供足够多的默认控件,但如果应用有更绚丽的效果要求,也会提供接口实现。高效性
作为UI引擎,掌控着足够完整的渲染流程,优化空间是相当大的。相对而言,难度也更大。这个高效反映在两方面,一是图形引擎的高效,一是脏区域识别的高效。
图形引擎的高效
第一个重要的点是下层图形引擎的选用
图形引擎的高效反映在两个方面:单体性能和复合性能。单体性能即渲染单个物体的性能,复合性能则是指在多个物体一起渲染的性能(多个物体一起渲染,有一些优化手段,比如作遮挡判断,消除非必要渲染,又比如作区域分划,多线程绘制各区域上的物体)。 图形引擎可以基于CPU渲染,也可以基于GPU渲染。就一般的UI渲染而言,CPU图形引擎优化得足够,倒也能满足要求,不会比GPU引擎差多少。识别脏区域
与游戏界面的实时变换不同,对普通应用UI界面的渲染而言,大部分情况下一个页面的大部分面积处于不变状态。变化的区域又称脏区域。如何尽可能多地识别不变的部分,并作渲染规避,是UI引擎需要完成的很重要的工作。
比较理想的UI引擎的设计结构如下图:
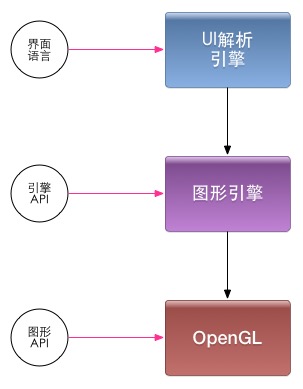 应用开发者可以在三个层次上去实现UI效果。从上往下,自由度越来越高,开发难度也会越来越大。
应用开发者可以在三个层次上去实现UI效果。从上往下,自由度越来越高,开发难度也会越来越大。 Android的设计
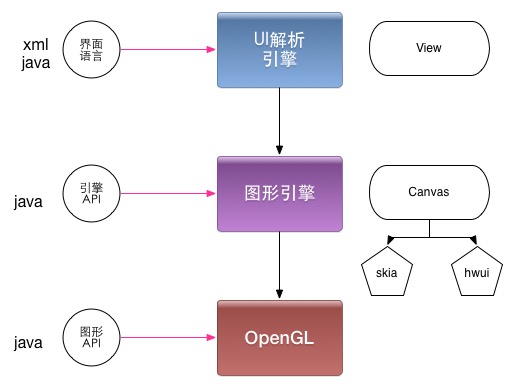
View
Android的控件和布局管理都抽象为View。部分View用于布局解析(各种Layout),部分View用于管理(复合View),部分View是实际的控件(TextView、ImageView、WebView等)。
具体的渲染流程完全取决于应用所选择的View的子类。 所有View组成一个树,布局时逐层创建树节点,渲染时逐级渲染。当调用invalidate刷新View时,由下往上逐层上报dirty区域。 具体可看这篇文章,写得比较清楚: 一个View无论其渲染流程怎样,都必须保证其绘制内容固定在屏幕的指定范围,这是Android上层显示的设计原则。对于使用系统的图形引擎的应用,这可以通过在大图层上划分一块区域,设置裁剪范围而实现。但如果不使用系统图形引擎,就只好新建一个图层,并将主图层对应位置挖洞。 在View的invalidate函数中,将需要重绘的View作标志。并将其区域与上一级View的脏区域作合并,最终反映到ViewRootImpl的mDirty中来。 invalidate顺着View树脉络,一层一层往上刷新。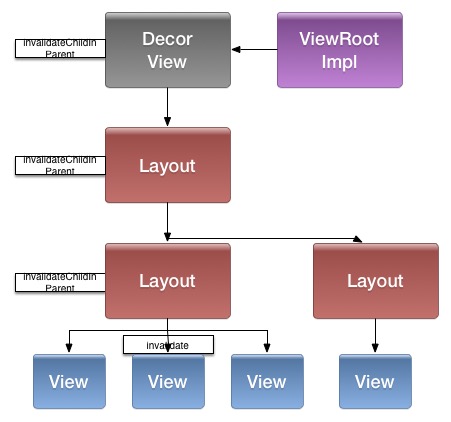 invalidate之后,该View即需要绘制,即是dirty的。
invalidate之后,该View即需要绘制,即是dirty的。 Canvas
Canvas是Android系统提供的图形引擎API,由于早期Android的图形渲染由Skia完成,Canvas接口也与Skia的API非常像。
绝大部分控件使用Canvas的API进行界面渲染,如TextView、ImageView及用户自定义,重载onDraw(Canvas canvas)的View。 比较特殊的是WebView,它不使用Canvas的API渲染,而是由Canvas获取Surface信息后,走web引擎渲染。绘制主线
触发
众所周知,ViewRootImpl类的performTraversals方法,是所有界面布局、绘制的入口,但这个方法是怎么触发的呢?
在应用初起、View更新(触发invalidate)、动画、创建新Surface等情形下,会通过 scheduleTraversals 方法,向 Choreographer 类注册一个回调,Choreographer 类是用来接受vsync信号的,这样,在LCD发出vsync信号之后(也即新一帧开启),该回调被执行,即doTraversal -> performTraversals。 详情参见:注:
1、performTraversals的调用是应用级的,也就是说,有可能会有多个应用去调这个函数。主流程

渲染流程
软件渲染
drawSoftware
简洁明快的流程: 1、调 surface.lockCanvas,取得渲染入口Canvas。 2、从顶层View开始,按树递归调用View的draw方法。在draw方法中,所有View中的onDraw实现被调用。 3、调 surface.unlockCanvasAndPost 第1步对应的下层逻辑还是有点复杂的: (1)dequeueBuffer获取一块新GraphicBuffer。 (2)将新GraphicBuffer锁定(lock),指明为CPU所访问。 (3)优化:如果存在上一帧所渲染的GraphicBuffer,且长宽与当前窗口一致,那么复制上一帧非dirty区域的内容到新一帧。如果不存在,将dirty区域设为全屏(即所有区域都要渲染)。 (4)将GraphicBuffer映射为一个SkBitmap,对应创建一个SkCanvas与之绑定,SkCanvas设置裁剪区域为第(3)步得到的dirty区域。 (5)SkCanvas包装为上层的Canvas传回。 第3步对应的下层逻辑就是 queueBuffer。 请注意,不是只需要绘制dirty的View的,因为View有可能会重叠,发生透明度混合,重叠部分影响到非dirty的View时,也应该绘制,Android并没有计算哪些View需要重绘,就笼统地让所有View执行onDraw方法。软件渲染流程中,布局、渲染、事件响应全部集中在主线程,比较容易造成阻塞。
硬件渲染
为何要有硬件渲染这套流程,而不是仅改造图形引擎为用gpu的呢?
这是因为直接按软件渲染那套流程走下来,是不适合用gpu渲染的,强行换用OpenGL实现,效率会低得可怜。 硬件加速中draw的实现在ThreadedRenderer.java之中(这是5.0的,不同版本可能有不同,重点看原理)。 1、把创建好的Surface扔给硬件加速的Renderer,供其初始化(eglCreateWindowSurface要用)。 2、更新显示列表(updateRootDisplayList):创建一个记录命令的Canvas,将View中对Canvas的draw操作变成记录命令,非dirty的View不需要重新记录。 3、执行渲染(nSyncAndDrawFrame)。这一步是放渲染线程里面发一个任务,让其做一次绘制,一般不需要等渲染线程绘制完成。 具体实现在 DrawTask的drawFrame函数,后续章节详述: frameworks/base/libs/hwui/renderthread/DrawFrameTask.cpp从设计而言,硬件加速的渲染流程要比软件渲染流程好一些,显示列表的存在,给复合优化带来可能,即使不用gpu加速,也都有优势。
关于硬件加速几个常见问题和误区:
1、为何开启硬件加速要额外的内存? 很多文章里面将其误认为是开启OpenGL所需要的额外内存,其实不然。OpenGL上下文的内存消耗不会达到MB级,这个额外内存是hwui引擎所需要的缓存,大头是字体。具体大小可以通过设置系统属性修改。通过 adb shell getprop,可查看相关的属性(ro.hwui开头)。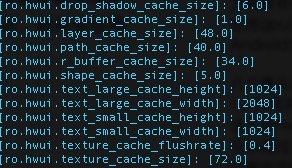 hwui内部机理是将文字解析到一个大的texture上,渲染具体文本时计算对应文字范围,取此texture中的一部分。因此有一个宽/高的设置,不像skia里面是一维的大小。 关于为什么要有字体缓存,可以看一下这篇文章: 另外,在Android系统内存不足时,会去部分回收这个Cache。 2、显示列表机制是否显著提升了UI渲染性能? 显著提升渲染性能靠的是GPU,显示列表机制是将GPU用上的一种方法。 由于Android早期API全部基于CPU渲染,因此在UI渲染时所有资源(最主要还是图像Bitmap)都在CPU所能访问的内存中。GPU渲染时,必须要把对应的资源复制到显存中。这一个复制的过程,自然不希望每一帧时都做一遍。 保存所有命令及相应资源到一个显示列表上,然后回放,是一个可取的方案,其最大的好处是应用开发者仍然可以按原先的API进行开发,只需要打开一个开关就能用到硬件加速。 3、硬件加速是否可以使所有的界面绘制都用上GPU? 答案是否。请看下面的“非主线渲染”。
hwui内部机理是将文字解析到一个大的texture上,渲染具体文本时计算对应文字范围,取此texture中的一部分。因此有一个宽/高的设置,不像skia里面是一维的大小。 关于为什么要有字体缓存,可以看一下这篇文章: 另外,在Android系统内存不足时,会去部分回收这个Cache。 2、显示列表机制是否显著提升了UI渲染性能? 显著提升渲染性能靠的是GPU,显示列表机制是将GPU用上的一种方法。 由于Android早期API全部基于CPU渲染,因此在UI渲染时所有资源(最主要还是图像Bitmap)都在CPU所能访问的内存中。GPU渲染时,必须要把对应的资源复制到显存中。这一个复制的过程,自然不希望每一帧时都做一遍。 保存所有命令及相应资源到一个显示列表上,然后回放,是一个可取的方案,其最大的好处是应用开发者仍然可以按原先的API进行开发,只需要打开一个开关就能用到硬件加速。 3、硬件加速是否可以使所有的界面绘制都用上GPU? 答案是否。请看下面的“非主线渲染”。 非主线渲染
就View层级设计而言,Android希望一个应用只有一个图层,并在这个图层上布局所有的控件,并且应用不用感知这个图层的内存所在,最多调Canvas接口即可,系统帮忙搞定图形渲染、Buffer循环、送显合成等繁琐事务。
但很可惜,这种方案不能满足所有需求: 1、对视频、照相等应用而言,它们需要直接访问物理内存(主要是硬件解码器和ISP等需要),把它们的显示放到一个图层的部分区域,不太现实。 2、所有UI操作和绘制集中在主线程,即使是硬件加速,也需要在主线程创建显示列表,做动画时,容易阻塞事件响应。 3、这种方案下,应用开发者无法自定义渲染流程,直接使用OpenGL等图形API进行开发,这样意味着使用不了游戏引擎。SurfaceView应运而生,它的原理,就是打洞覆盖:另起一个图层(即新建一个Surface),并把主图层的相应区域置为透明,然后渲染就发生在新图层中,最终显示效果自然是依赖SurfaceFlinger的叠加。
用法参考: 其中,SurfaceHolder往下会对应着一个Buffer循环队列,这个是物理共享内存的抽象,因此可以做为视频、相机预览流的指定输入。 网上的教程中,SurfaceView的用法都在另一个线程中,先lockCanvas,调用Canvas的接口绘制画面之后,调unlockCanvasAndPost。这种方式,便是典型的调CPU引擎-Skia渲染的方式。 尽管应用开发者可以用SurfaceView直接开发基于OpenGL渲染的程序(SurfaceHolder可以用于创建OpenGL上下文),Google还是很仁慈地提供了GLSurfaceView,这个类帮开发者创建好了上下文和相应的渲染线程,开发者可以直接在回调函数中使用OpenGL,简单很多。请注意:
1、SurfaceView不会自动起一个单独的线程去渲染,只是这个View上面的渲染可以在任意线程完成。开发者执意在主线程去渲染这个View,也是可以的,就像以前QQ某一版的引导页一样,CPU差一点的机器滑都滑不动(净给我们这些做系统优化的出难题)。 2、SurfaceView虽然可以把渲染流程移到另一个线程执行,但它的存在同时增加了SurfaceFlinger的合成负担(图层数增加),不要以为这就是一个很高效的View,如果是出于提升性能的目的而使用,请仔细权衡一下得失。 3、硬件加速属性不影响SurfaceView的渲染方式,lockCanvas必然得到用CPU绘制的Canvas。要在SurfaceView中用上GPU渲染,只好自已建上下文或用GLSurfaceView,接入3D引擎。补充,2015.8.14之后,Android提供了一个lockHardwareCanvas方法,用此方法可以得到硬件加速的Canvas,Android 6.0上已经可以使用,这可是个大福音。 4、SurfaceView系列的渲染流程不在performTraversals主线中,因此一般也不受vsync限制(当然,可以设计流程使之受限),也不会像主线渲染必须由invalidate触发。不过,如果渲染太快,在下层显示的窗口管理模块,可以使之阻塞在申请Buffer的步骤上。Android的设计吐槽
Android的发展也有些年头了,图形显示部分更是一改再改,几乎面目全非,总算是满足了手机硬件发展的需求,实现了一个比较高效,对开发者相对友好的界面绘制系统,相对于其他系统来说,其实也算优秀了。然而,作为一个逐渐演进的复杂系统,背负着不少历史的包袱,总会有各种各样的不合理,这里就来吐槽一下:
1、主线程单一管理界面 个人认为的最大槽点,没有之一。所有UI操作集中到一个线程后无法并行,而measure/layout/draw都是耗时大户。在应用启动、屏幕旋转、列表滑动等场景,屡屡出现性能问题。ART模式开启,加快了java代码执行效率后,好了一些,但指标仍然不好看。2、脏区域识别之后并没有充分地优化
软件渲染时,尽管限制了渲染区域,但所有View的onDraw方法一个不丢的执行了一遍。 硬件渲染时,避免了没刷新的View调onDraw方法更新显示列表,但显示列表中的命令仍然一个不落的在全屏幕上执行了一遍。 一个比较容易想到的优化方案就是为主流程中的View建立一个R-Tree索引,invalidate这一接口修改为可以传入一个矩形范围R,更新时,利用R-Tree索引找出包含R的所有叶子View,令这些View在R范围重绘一次即可。这个槽点其实影响倒不是很大,大部分情况下View不多,且如果出现性能问题,基本上都是一半以上的屏幕刷新。
3、图层分配方案比较浪费内存和内存传输带宽(DDR带宽)
下图是对小米平板上相机应用 dumpsys SurfaceFlinger的一个结果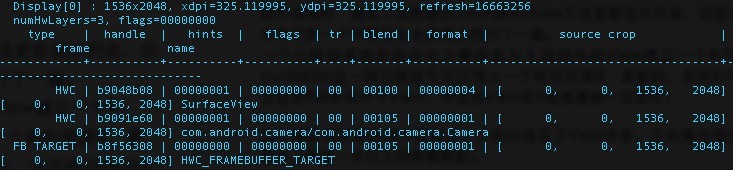 由上图可以看出,SurfaceView的Layer(相机的预览Surface)和com.android.camera的Layer(主渲染流程的Surface)是一样大的,都差不多占了全屏。 但实际上,com.android.camera只有几个图标,这个Layer绝大部分是透明的。考虑到TrippleBuffer机制,按透明部分约为1024*2048的大小算,就浪费了1024*2048*4*3=24M的内存。 而且在SurfaceFlinger作合成时,透明部分也要参与,按最省内存传输带宽的在线合成(只需要一读)方式,预览帧按30fps算,透明部分所需要的DDR带宽就是8M*30/s = 240M/s。一般手机上的DDR带宽才800M/s(高端手机应该有1600),这就占用了几乎1/3。
由上图可以看出,SurfaceView的Layer(相机的预览Surface)和com.android.camera的Layer(主渲染流程的Surface)是一样大的,都差不多占了全屏。 但实际上,com.android.camera只有几个图标,这个Layer绝大部分是透明的。考虑到TrippleBuffer机制,按透明部分约为1024*2048的大小算,就浪费了1024*2048*4*3=24M的内存。 而且在SurfaceFlinger作合成时,透明部分也要参与,按最省内存传输带宽的在线合成(只需要一读)方式,预览帧按30fps算,透明部分所需要的DDR带宽就是8M*30/s = 240M/s。一般手机上的DDR带宽才800M/s(高端手机应该有1600),这就占用了几乎1/3。